Setting up Python and Jupyter for your First Machine Learning Environment
Want to install Python and build an environment for working with data? You’ve come to the right place!
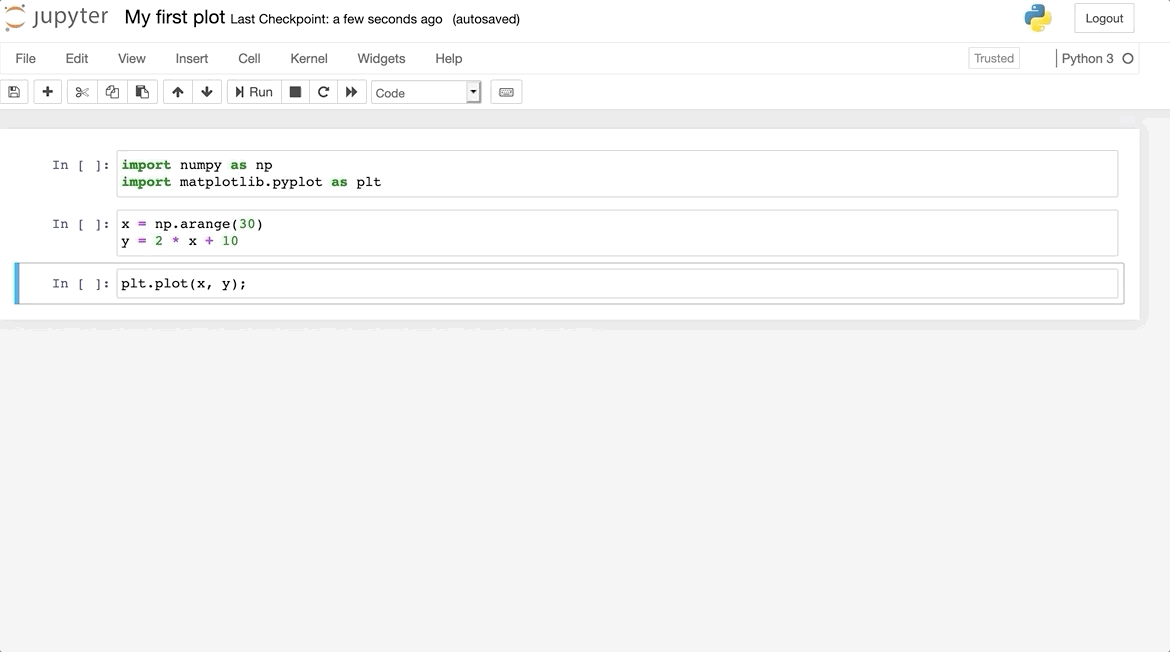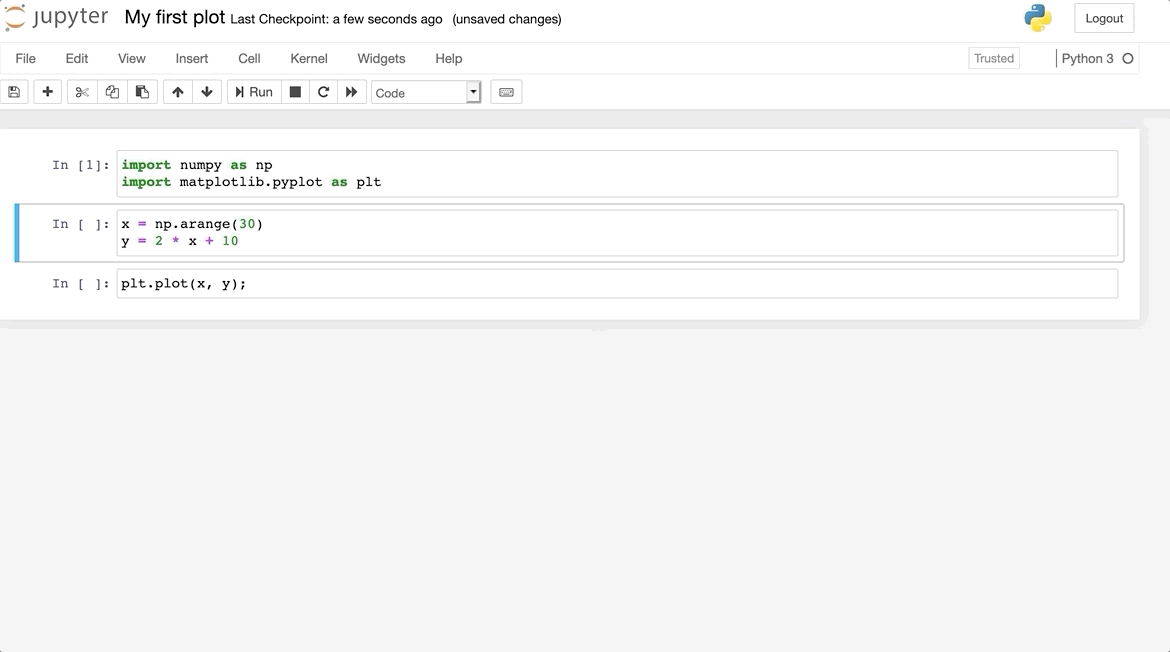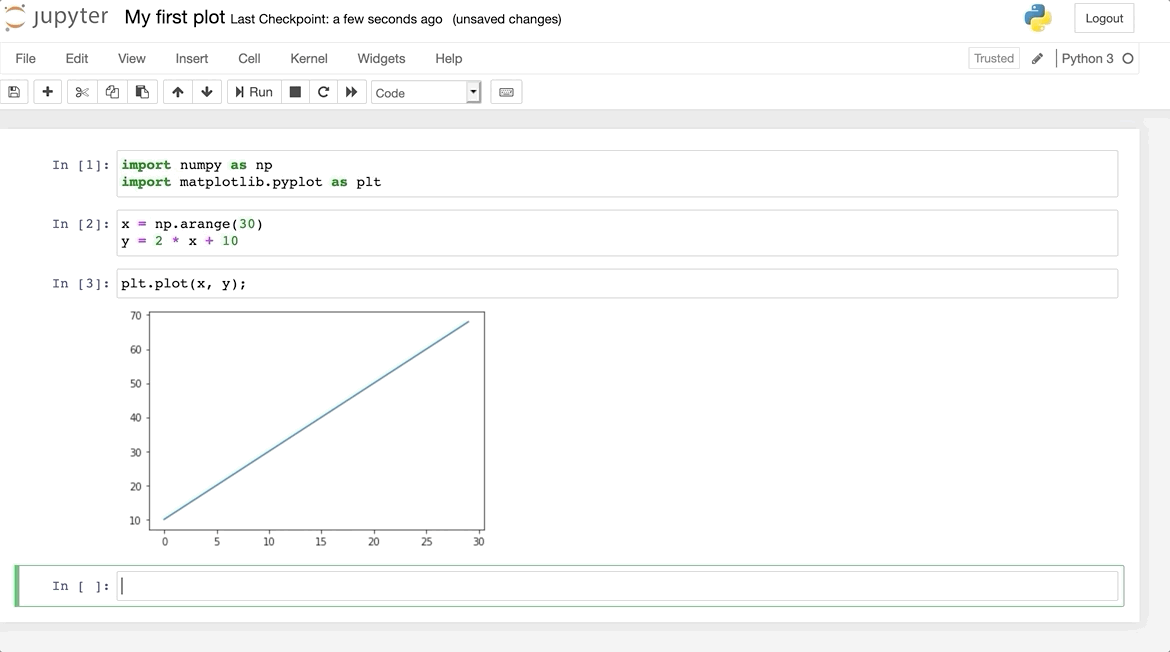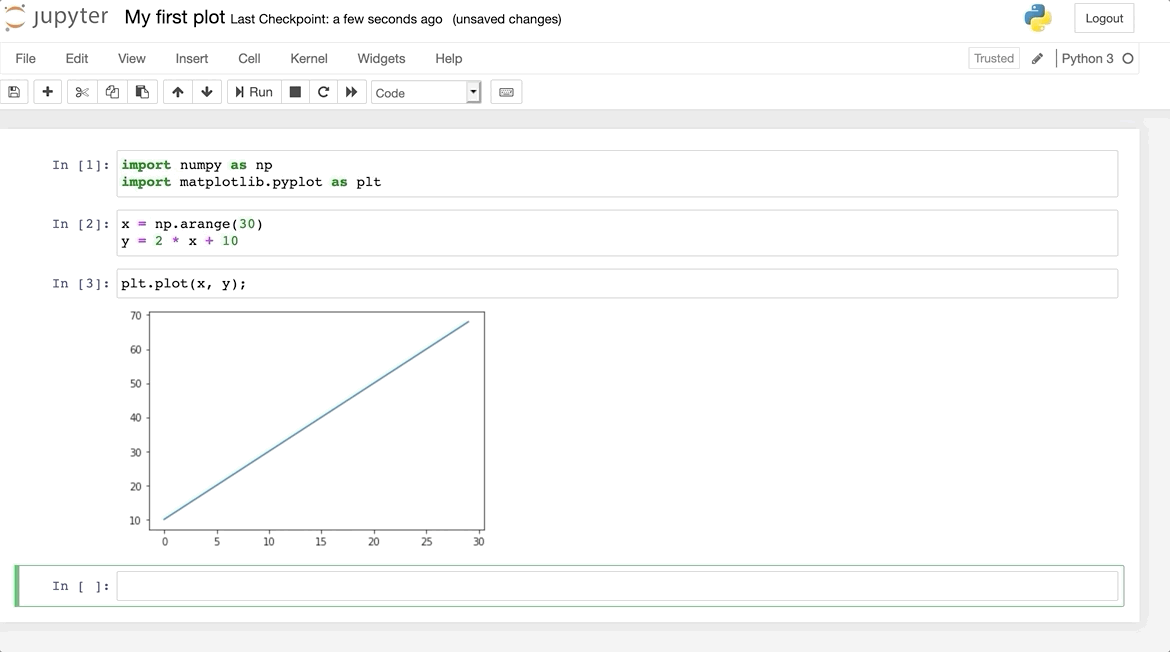
Is an entire Python installation tutorial really necessary?
One of the most common difficulties people have when getting started with Python is the installation. Folks frequently have issues not only downloading Python itself, but managing the external tools (we call these libraries or packages). So, in short, no – but I hope that this will empower you to take advantage of an advanced setup workflow to avoid these common issues!
The plan
I’m going to walk you through using conda to build your first data science environment and hopefully avoid unnecessary trouble with what can be a messy install process.
I’m going to assume you have a little bit of experience using a terminal or command prompt, though anything we do within the terminal should be google-able if it’s confusing.
Let’s get started!
Installation
-
Getting
conda, our fancy new package managercondagives us the ability to download python and other useful packages into an isolated environment. What this means is that we don’t have to worry about breaking anything when we need to install a new tool because we can put everything directly into a safe, isolated box - ourcondaenvironment. If anything doesn’t go the way we want, it’s okay! We can get rid of the environment and make a new one. If you want more background onconda, check out the documentation here.This process is a little easier if you’re using MacOS or Linux, but Windows should work great! As I cannot test Windows commands on my machine, Windows users should follow the documentation linked below very closely. The respective links to download
condafor each operating system are found in the following locations:It doesn’t matter whether you download
Anacondaorminicondain most cases. Both give you thecondatool (minicondahas less bloat so I prefer it myself). Windows users may benefit from a fullAnacondainstall to take advantage of theAnaconda promptterminal.To verify this step was done correctly, open a terminal/command prompt instance and type in
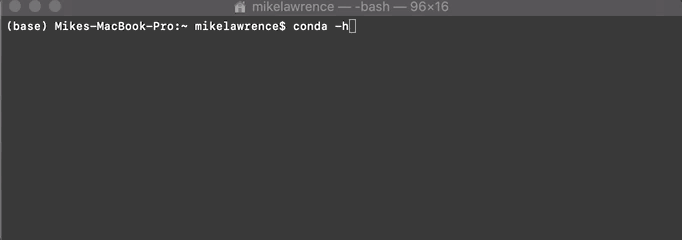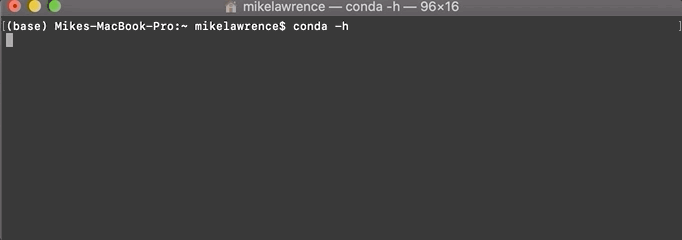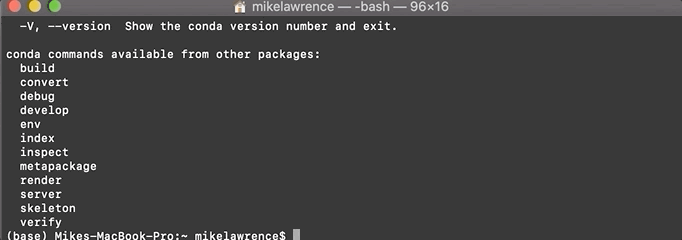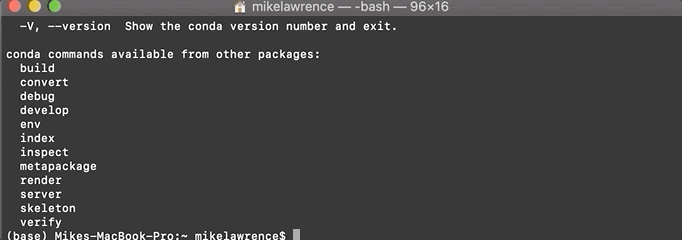
conda -h(this asks the program for help, telling you the options available). Ifcondaisn’t recognized, you may need to restart your terminal. If problems persist, look back at the installation link for pointers.If you see a bunch of details about using the program, congrats, you’re nearly done!
-
Creating our data science environment
At this point,
condais working for you. Making a new environment isn’t as scary as it may sound! In the data science yml file in this tutorial’s repo, you’ll notice that there is a Python version and many packages specified. These packages include common data science tools likenumpyfor fast math,matplotlibfor making plots,jupyterfor running notebooks,scikit-learnfor off-the-shelf machine learning, and bothtensorflowandkerasfor getting your hands on the newest machine learning models. We also includepymc3which, personally, I think is one of the best tools you can learn in this list as it provides a powerful interface for Bayesian machine learning. Let’s continue.We’re going to get these installed on your machine with the following few steps:
a) If you haven’t already, download
data-science-environment.ymlor copy and paste its content into a file on your computer with the same name.b) Find the path to its location. For example, for me it would be at
/Users/mike/Documents/GitHub/Python-for-Data-Science/data-science-environment.yml. The details of getting the path vary among operating systems, but it’s usually a right-click option. Google this if you’re unsure.c) Open your terminal back up within the folder that has our
.ymlfile, or navigate to it using thecdcommand. We can now build our Python environment! The command is:conda env create -f data-science-environment.ymlIt will likely ask you if you’d like to install the packages from our
.ymlfile with a simple[Y/n]. Confirm and letcondahandle the rest! -
Accessing our Python environment Congratulations! You now have a Python environment available with a ton of great data science tools!
Accessing these packages is really simple. Since our environment is called
data-science-environment, we make the python environment available with:conda activate data-science-environment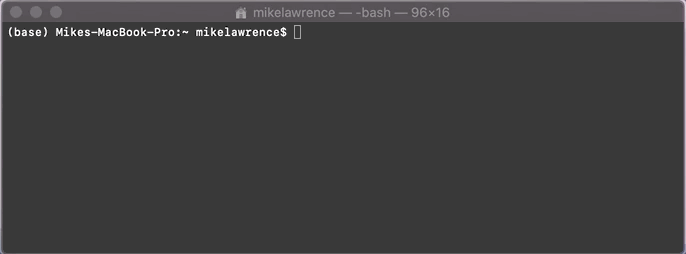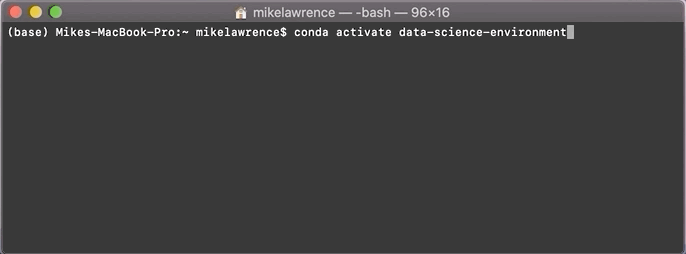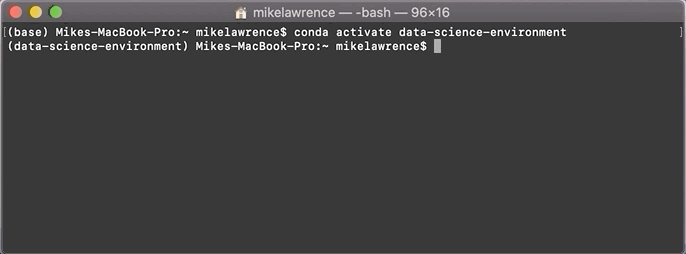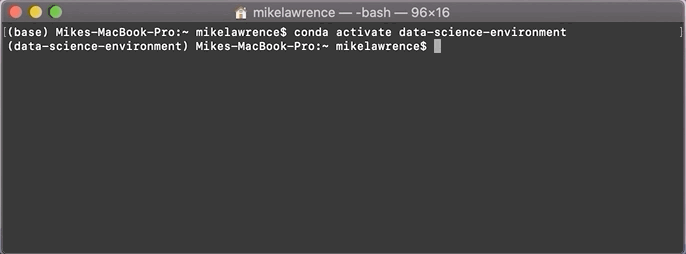
…and that’s all there is to it! If this environment is active, you can run Python scripts using any of the powerful packages with no additional effort, or even modify the .yml file to create a new,
reproducible environment of your own! Try running ipython to start an interactive session right away, then pat yourself on the back for your diligence.
Optional: Set up ability to choose your environment within Jupyter notebooks (kernels)
Jupyter notebooks are a fantastic tool for exploring data and prototyping new data-oriented code. We can run them from within our environment by simply calling,
jupyter notebook
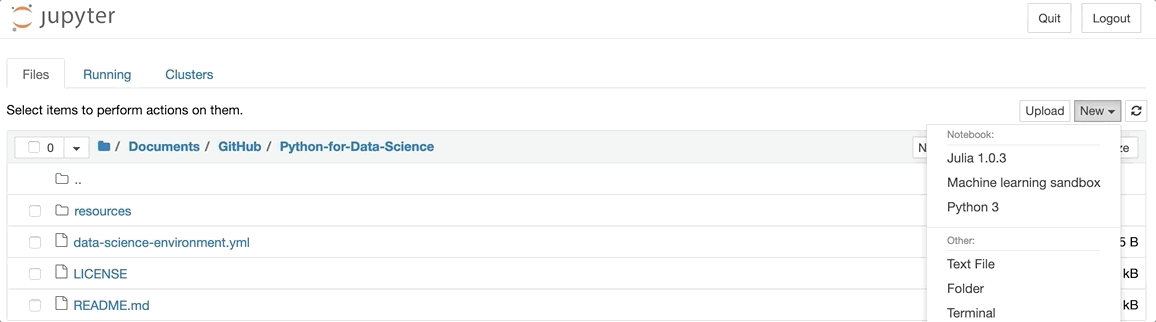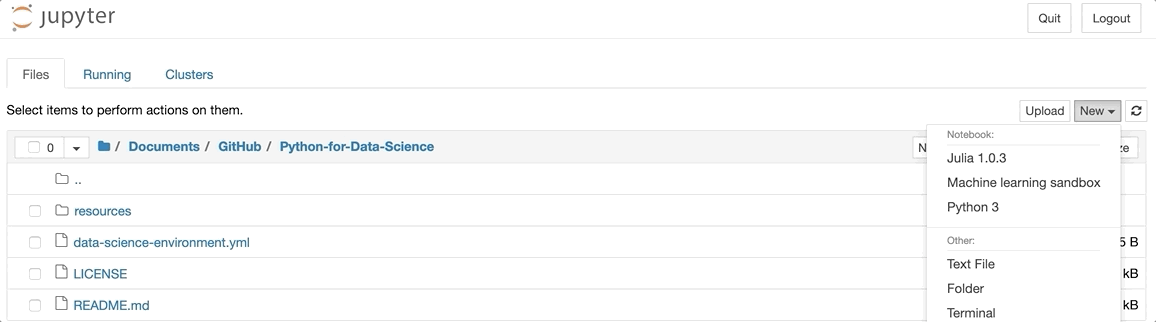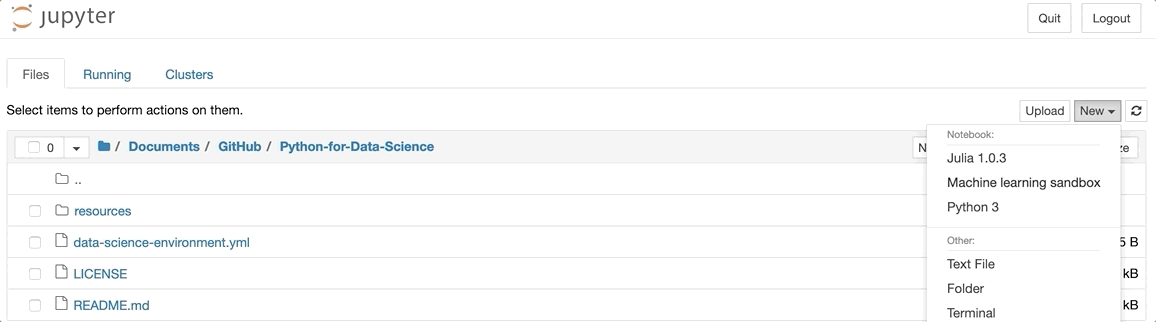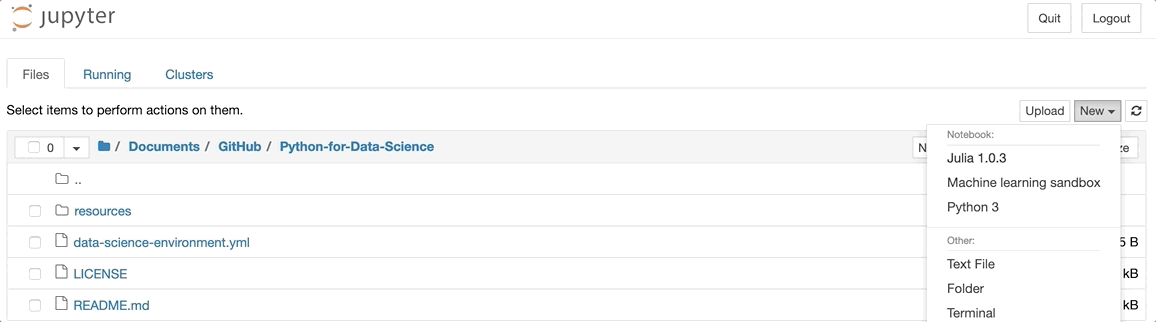
and then opening a notebook with the “new” button in the upper-right corner of your browser. Here you should see the option to use Python 3, and since you’re using your new environment, you’ll have access to some great packages! But what if you have multiple projects? We can add one extra layer of configuration - the ability to choose which conda environment to run code from. With one extra line of code, we can select our computing environment with ease!
To do this, we’ll use ipykernel.
Run the following (taking care to use conda activate to run within your environment),
python -m ipykernel install --user --name data-science-environment --display-name "Whatever name you want here"
Then, voila! I chose “Machine learning sandbox” for my display name, and you can see that we now have choices of what environment to use!
Notice that there’s a Julia kernel that got added as well; we aren’t limited to Python!
Thank you for reading, and happy computing.