What can you find by webscraping job posts on LinkedIn?
I’ve been scraping LinkedIn for a while to generate summaries of high level job stats in the tech ecosystem.
The tech ecosystem on LinkedIn
Tech is an extremely competitive space. It is known for its high-risk, high-reward approach to doing new things, and offers a wide variety of challenging work for those that don’t mind being in front of a screen all day. To better understand what the tech world is like from a job searcher’s perspective, I decided to dig into LinkedIn to uncover some of the high-level trends in tech hiring.
The typical LinkedIn job post
There are two views into a job post on LinkedIn: the site’s UI and the underlying HTML structure. The UI is what the vast majority of people will find useful. It may have information about the job’s responsibilities, the company mission, skills the employer is looking for, and more. LinkedIn may supplement this view with additional information, such as estimated size of the company, or an estimate of the role’s salary bands.
The second type of view - the underlying HTML - is interesting from a data perspective, however, as it is the key to programatically accessing LinkedIn.
The why and how of webscraping
If the job post information is gold, the HTML representation is our crude ore. It contains a text representation of everything we see on our screen, though not as human-friendly. It is, however, machine-friendly. All of this to say that if you want to understand any web trends in bulk, it will usually require understanding how to extract information from HTML.
“But how can we access the underlying HTML and get what we want?”, you may ask. Luckily for us, many super smart people made tools in Python for parsing HTML. My go-to is called BeautifulSoup. In addition, loading the HTML representation of a webpage is also extremely easy in Python, with the requests library making this possible is maybe 2 lines of code.
I am not going to teach webscraping here, but allow me to explain the rough steps for our use-case.
1) Load raw HTML into Python 2) Identify which information from the page you want to extract 3) Use BeautifulSoup to grab the relevant information 4) Save your shiny new data wherever you’d like
Not so bad, right?
Results
I update my scraped data multiple times per week, and plan to automate it with a scheduler, so the most up-to-date results will be in my Git repo. That said, let’s look at a snapshot of the results so far.
Unique values in the dataset
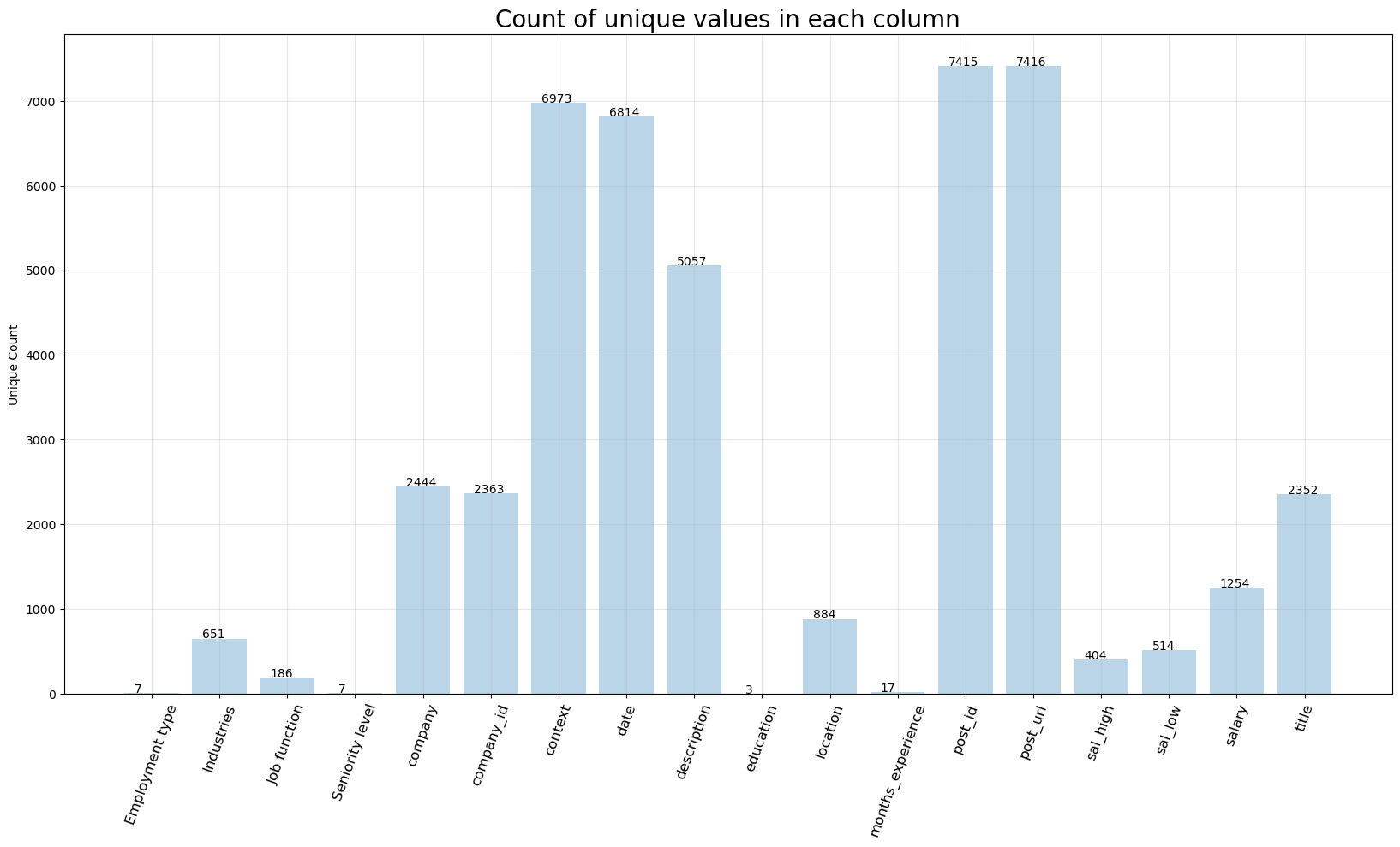
Before you dive into the data, here is a breakdown of how many unique values are in the dataset.
The column post_id tells you how many total unique posts there are, while the rest are indicators of how much variety is in the dataset.
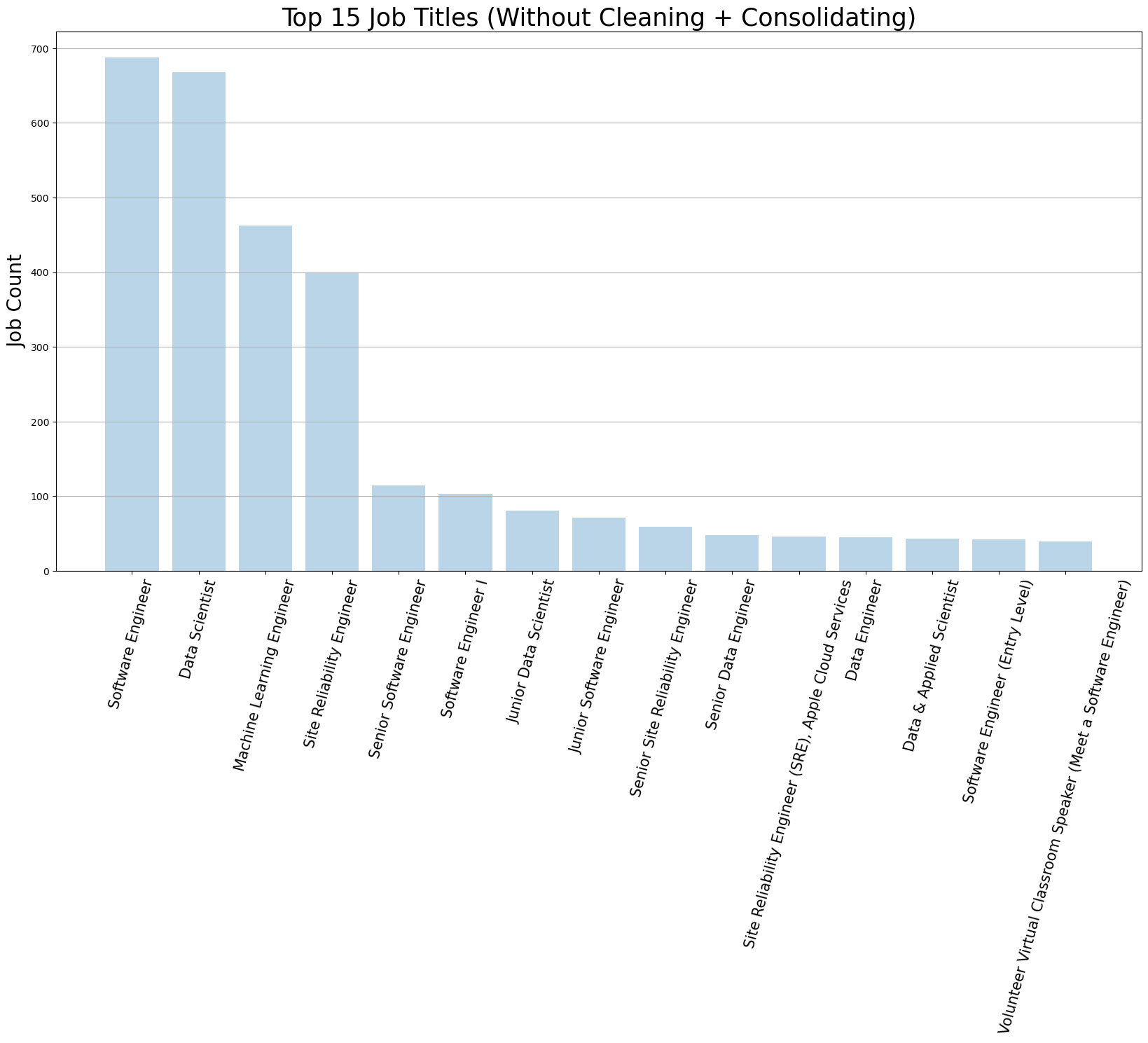
Top job titles
I scrape a handful of keywords, such as “data scientist” and “software engineer”, which biases these results. Here is the breakdown of top job titles in the dataset without any cleaning (example: data scientist and senior data scientist are two different titles though could arguably be treated as one category).
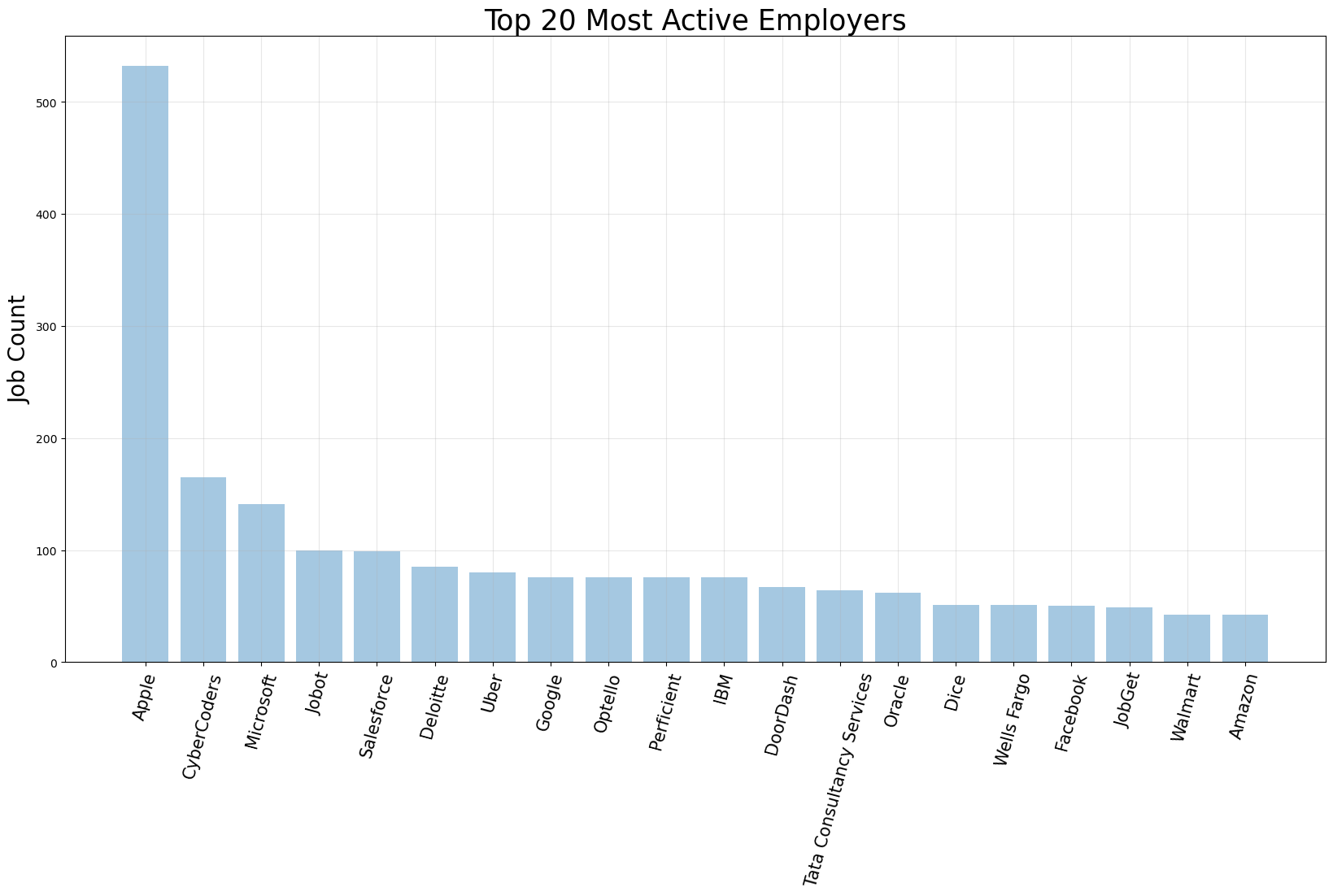
Top companies
These are the top companies by number of job posts. Results are biased by the time period I scraped data, which has not been random. This bias will average out over time.
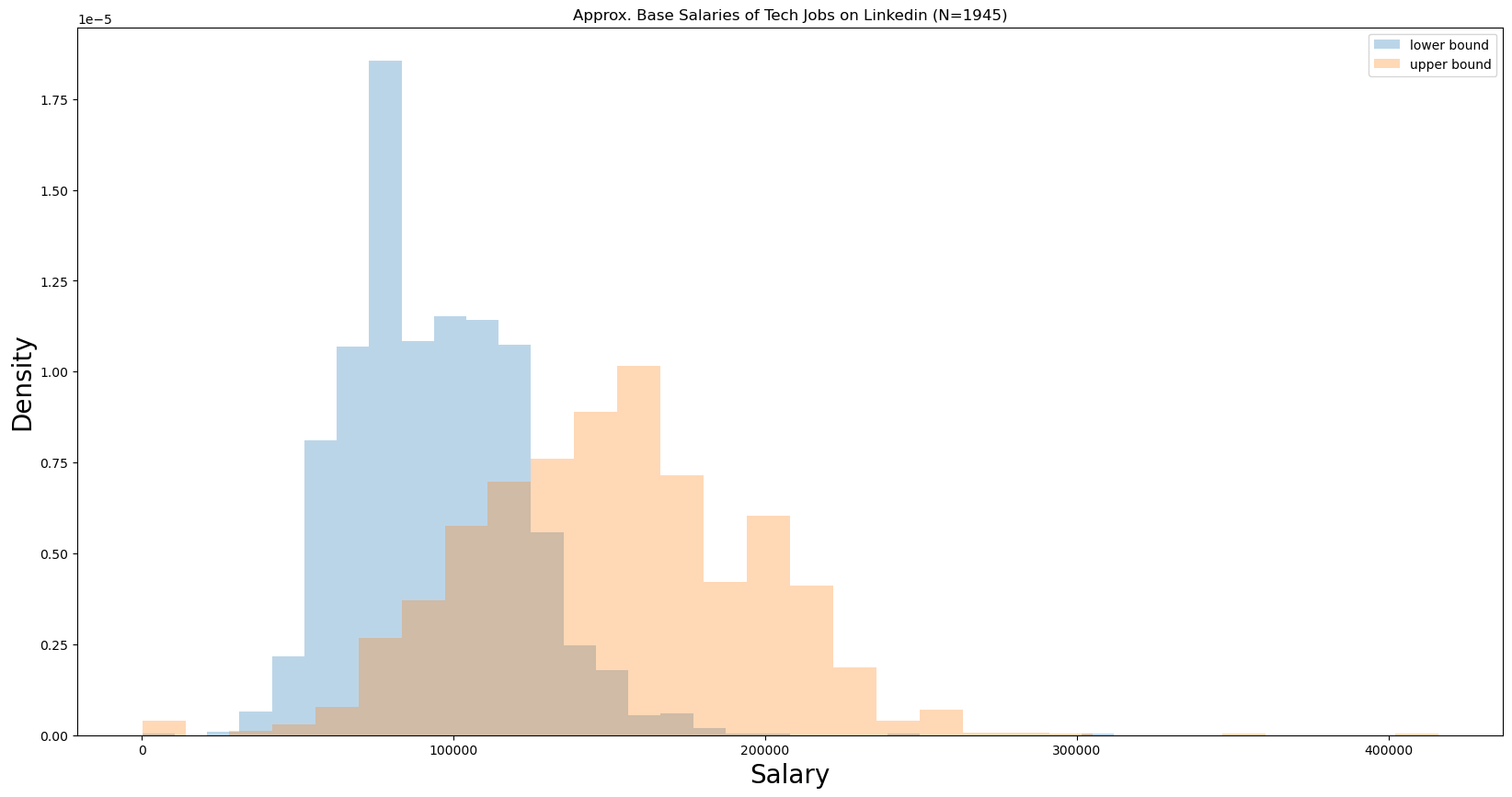
Salary Data
Only a fraction of the posts contain LinkedIn’s salary estimates. Tech is known to give substantial compensation on top of salary as well (stock, etc), so don’t use these numbers to negotiate total compensation - you can likely do better :)
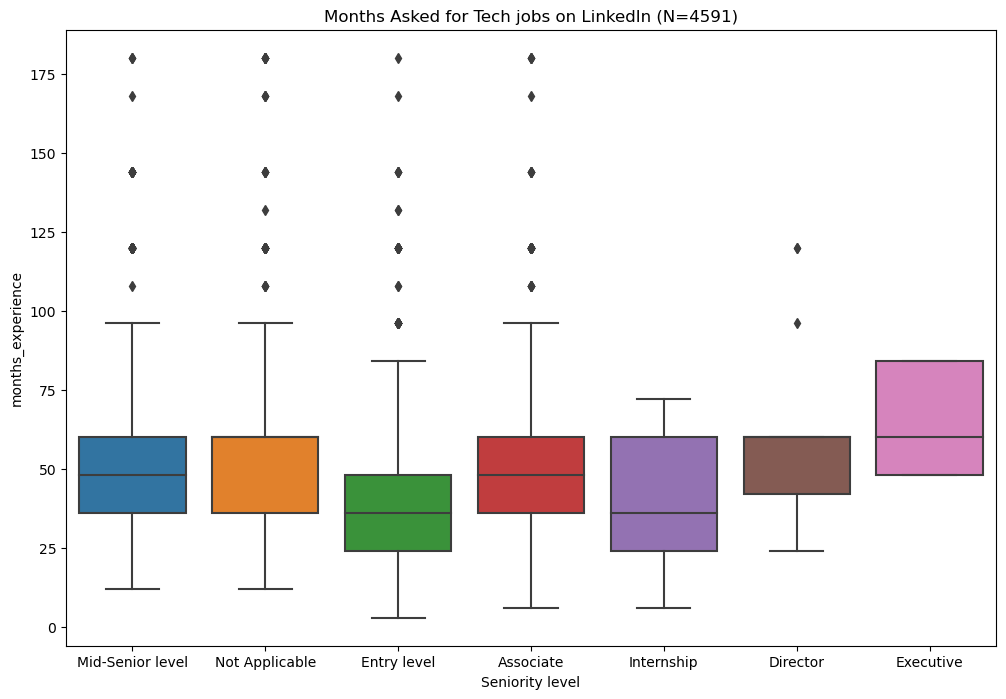
Years of Experience
Not all the metadata is reliable. One trend that stands out is in the amount of experience needed for a role. No matter the job seniority level, the distribution of experience asked is consistently in the same range. This suggests that experience ranges aren’t taken seriously by job posters, at least when LinkedIn asks for it. The actual range is much more likely to be reflected in the job description.
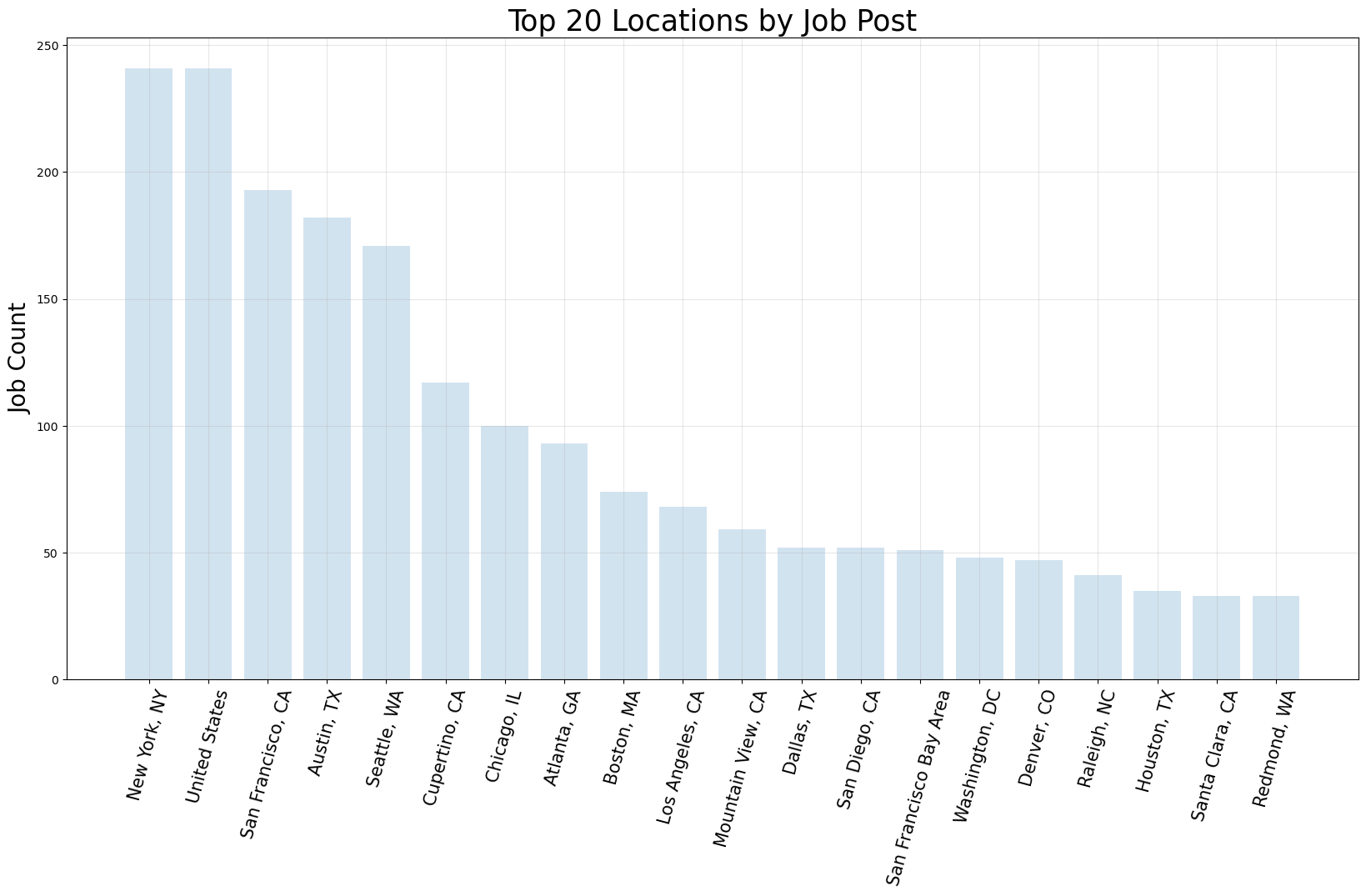
Top locations for tech jobs
Summary
Whether you are interested in webscraping, getting a new job, or maybe both, I hope you learned something interesting.
Cheers!